The Challenge of Human Opinion at Machine Scale
As AI systems become more sophisticated, one critical question emerges: how do we incorporate reliable human judgment into AI training data without sacrificing speed or consistency? The answer lies in what we call the Distributed Human Opinion (DHO) layer—a framework that captures authentic human perspectives at the scale AI demands.
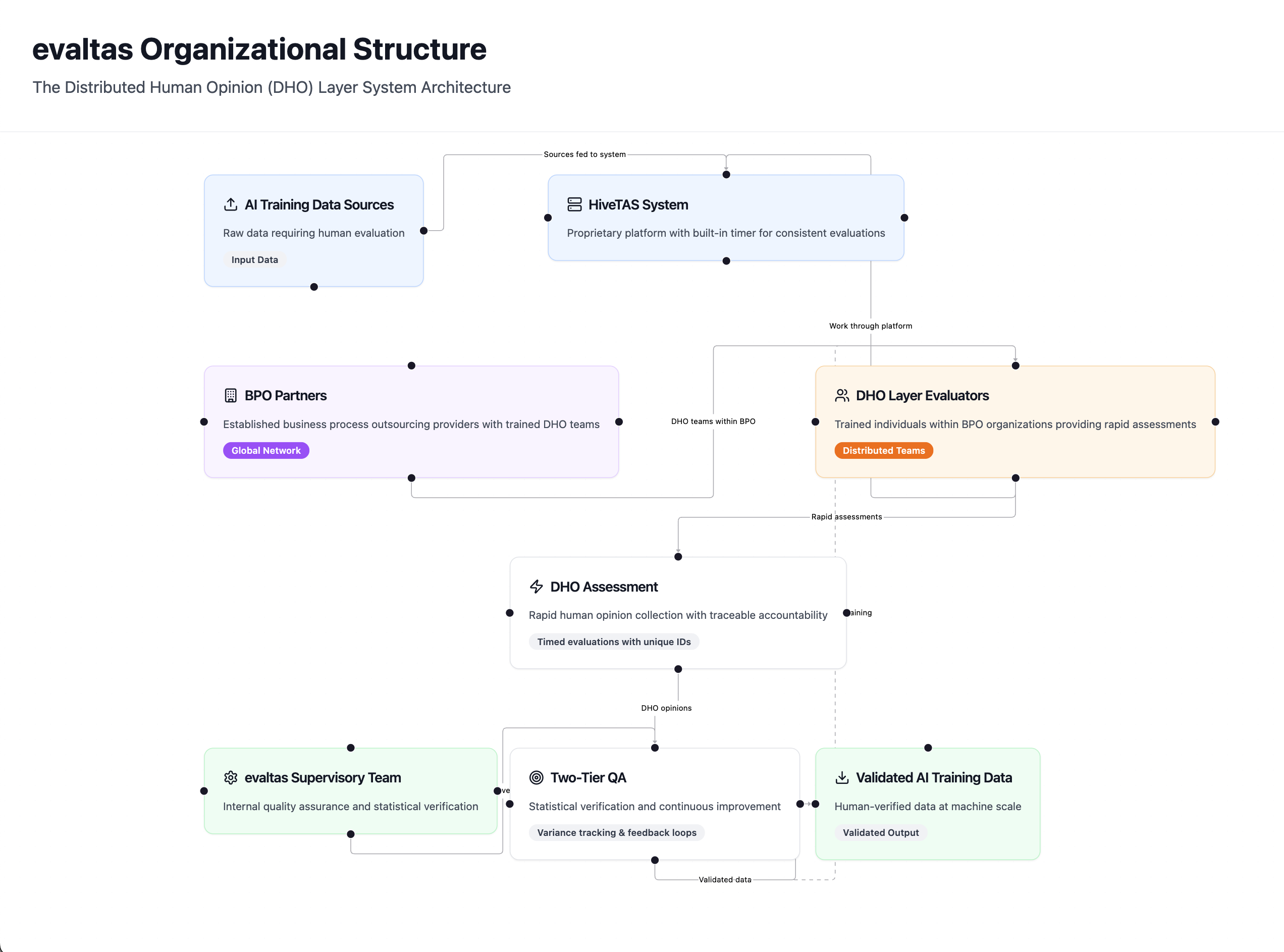
What Is the DHO Layer?
The DHO layer is our systematic approach to recording human opinions about AI sources at unprecedented scale. Think of it as quality control for the information that trains tomorrow’s AI systems, but designed for the reality of processing millions of data points.
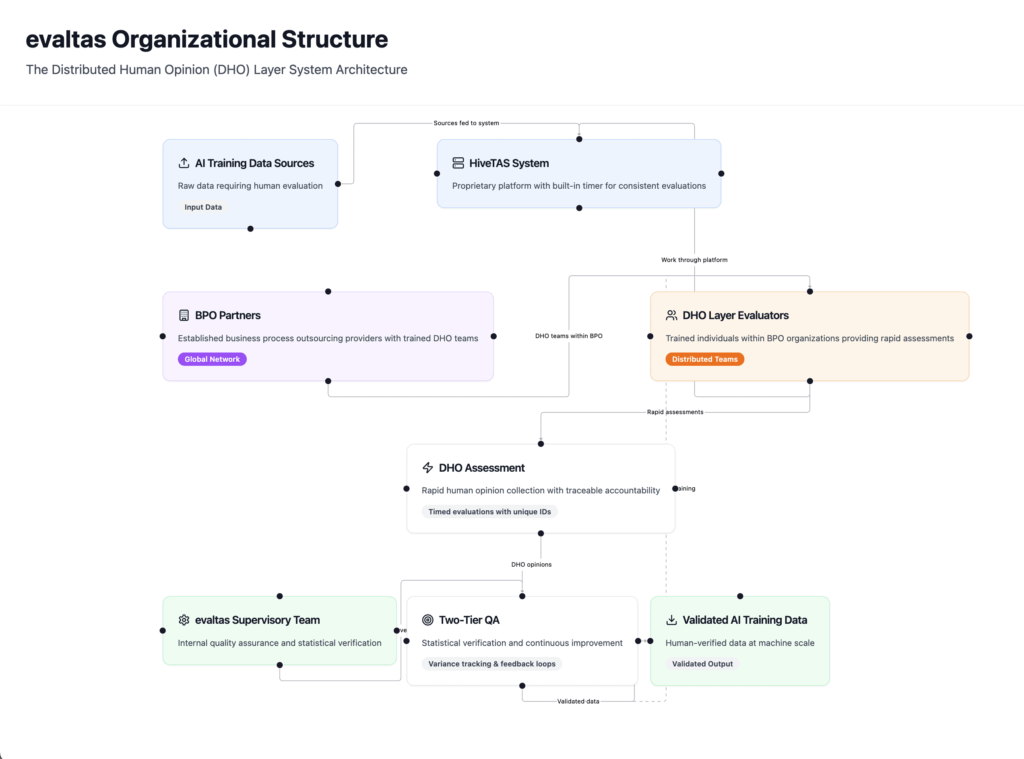
Here’s how it works:
The HiveTAS System: Our proprietary platform presents sources to human evaluators with a built-in timer, ensuring we capture genuine first impressions while maintaining consistent cost-per-opinion economics. This isn’t about rushed decisions—it’s about replicating how humans naturally assess information credibility in real-world scenarios.
Distributed Expertise: We partner with established Business Process Outsourcing (BPO) providers like Lionbridge, each bringing trained individuals who work within our HiveTAS ecosystem. This distributed model gives us global reach while maintaining quality standards.
Traceable Accountability: Every opinion is tagged with a unique identifier that traces back to the individual evaluator. This creates a certificate of conformity—complete transparency about who made each assessment and when.
The Two-Tier Quality Assurance Model
Raw human opinion isn’t enough. Our EvalTAS supervisory team provides the critical second layer:
Statistical Verification: Our internal team evaluates a statistically significant percentage of DHO assessments without time constraints, providing deeper analysis that validates the rapid-fire DHO evaluations.
Continuous Improvement: When our supervisory team identifies opinions outside expected parameters, those insights become training inputs for the DHO layer. This creates a feedback loop that continuously improves evaluation quality.
Quality Metrics: We track variance between DHO and supervisory assessments, building comprehensive quality assurance metrics that inform both individual training and system-wide improvements.
Why This Matters for AI’s Future
As we race toward more powerful AI systems, the temptation is to automate everything. But human judgment remains irreplaceable for nuanced assessments of credibility, bias, and manipulation. The DHO layer solves the false choice between human insight and machine scale.
The result? AI training data that combines the speed and consistency of automated systems with the nuanced judgment that only humans can provide—at the scale modern AI development demands.
Leave a Reply